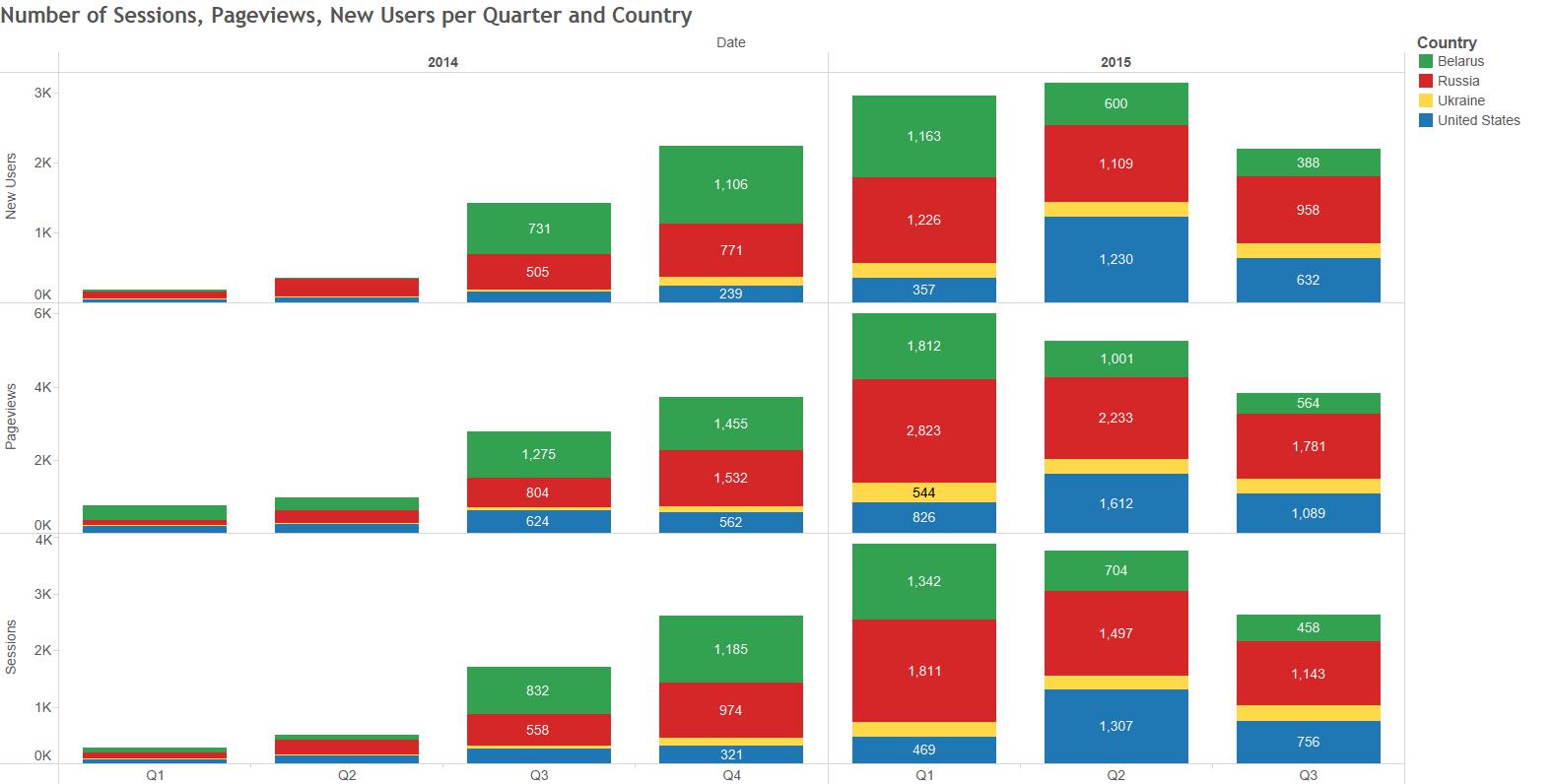
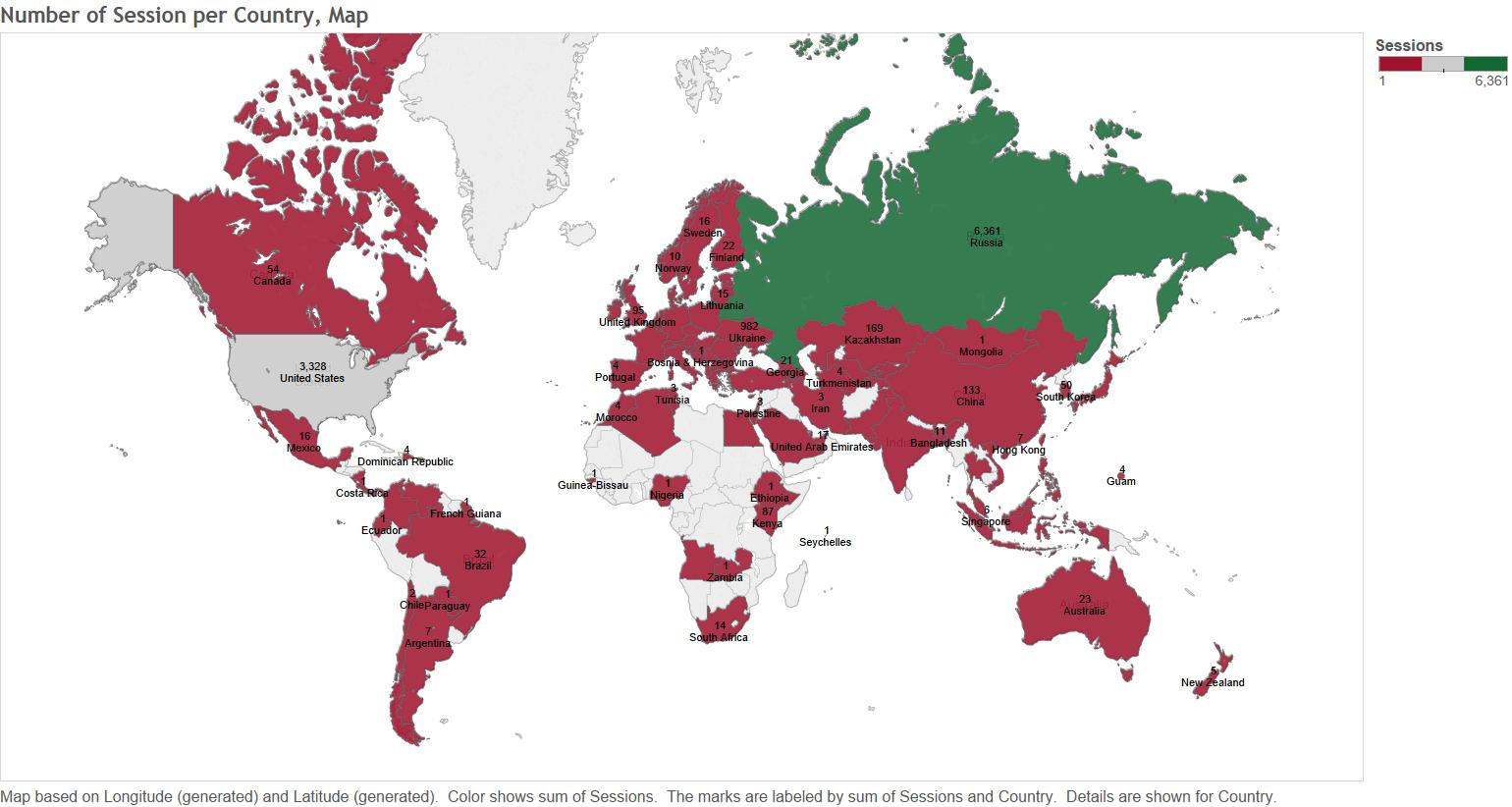
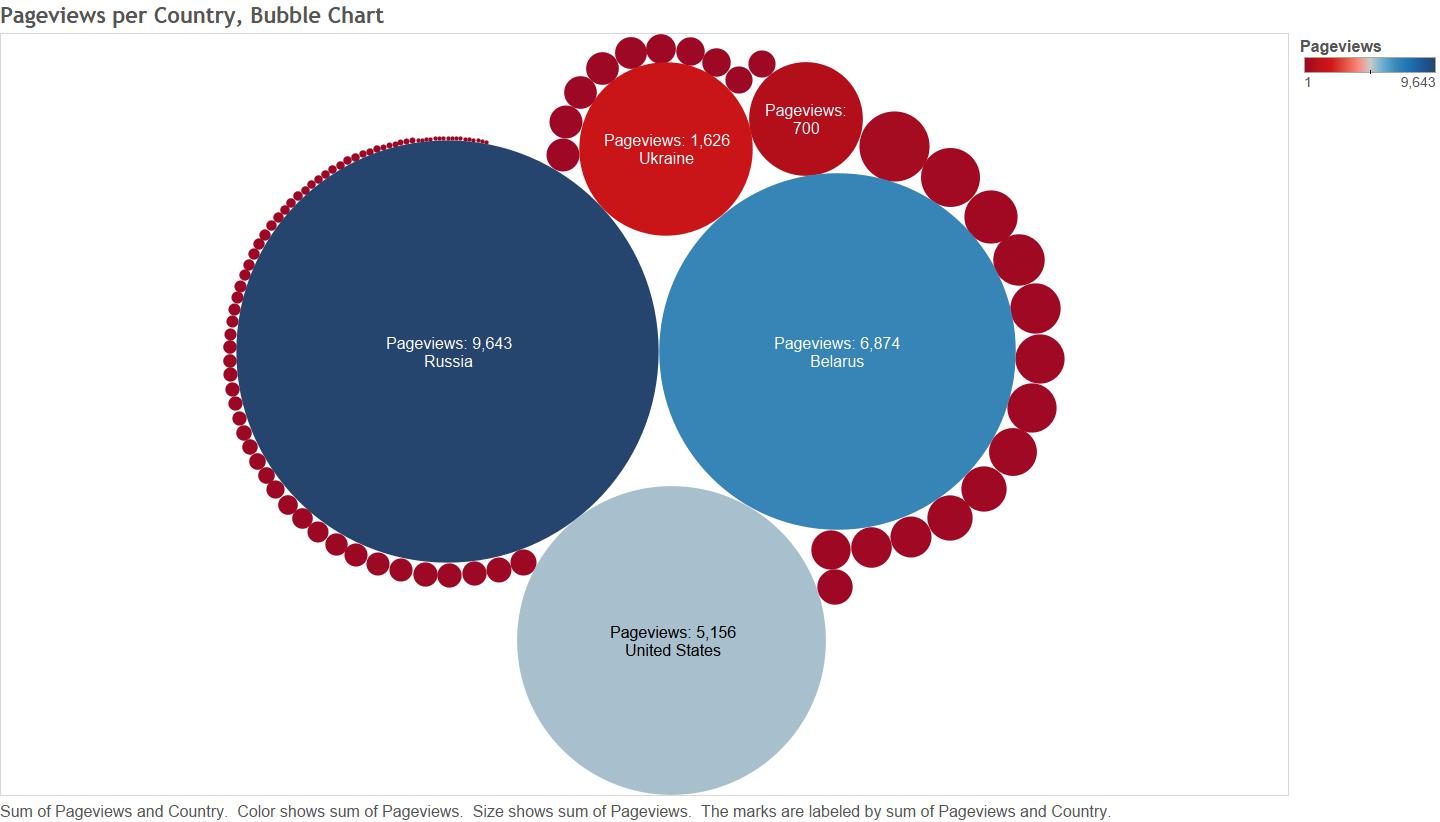
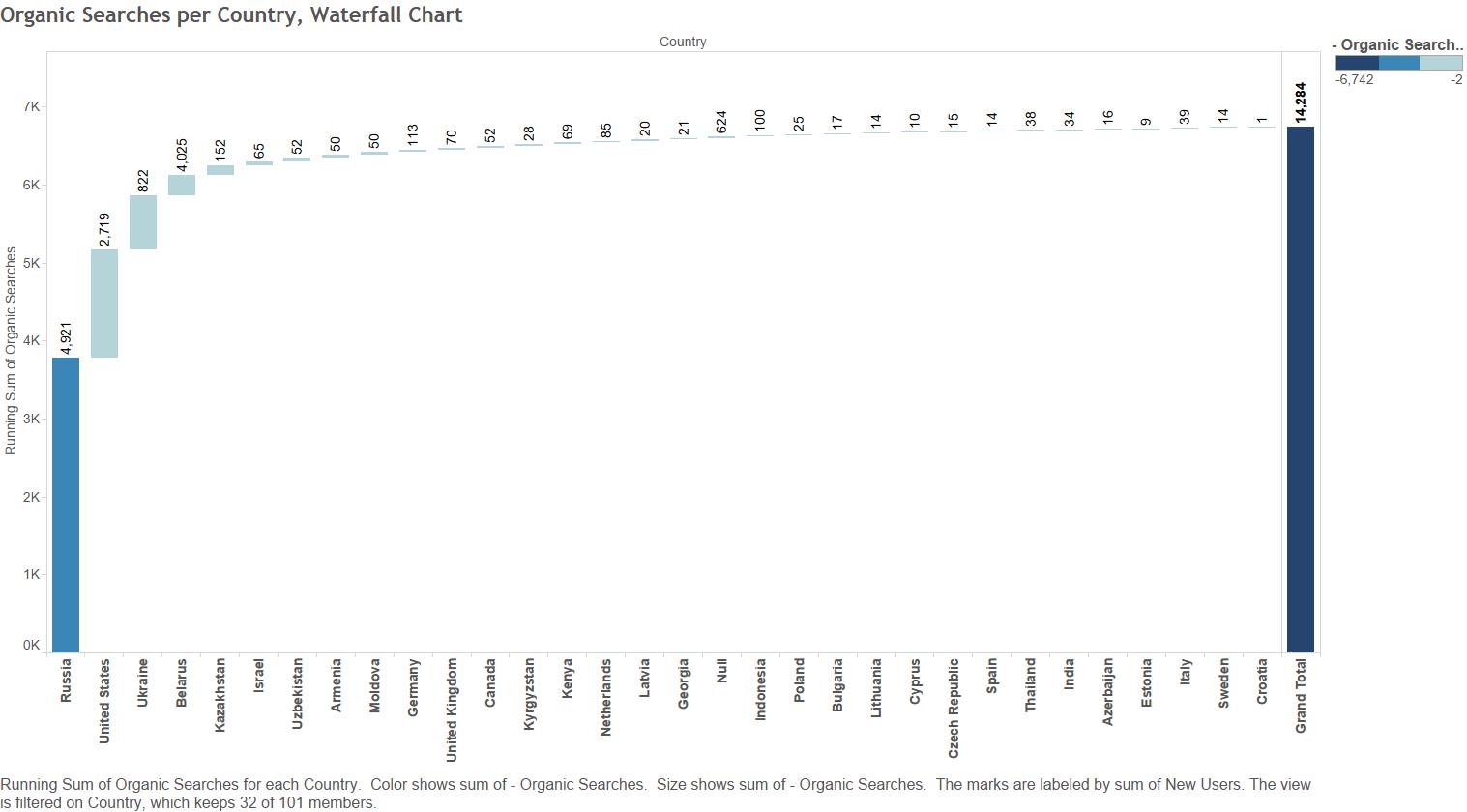
You will need RGoogleAnalytics package to extract Google Analytics data in R. The package was developed by Michael Pearmain, and it provides functions for accessing and retrieving data from the Google Analytics API. This article is based on the package’s supporting documentation. To download the documentation use this link: RGoogleAnalytics documentation.
First, install the package RgoogleAnalytics. It requires the packages “lubridate” and “httr” to be installed as well.
install.packages("RGoogleAnalytics")
install.packages("lubridate")
install.packages("httr")
library(RGoogleAnalytics)
library(lubridate)
library(httr)If you have problems with downloading the packages, check your R version. RGoogleAnalytics requires R version 3.0.2 or newer.
Then, you will use the Auth function to authorize the RGoogleAnalytics package to your Google Analytics Account using Oauth2.0.
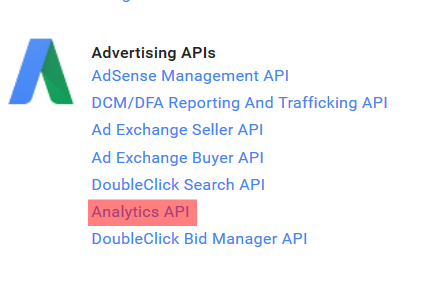
The function Auth expects a Client ID and Client Secret. To get these, you will have to register an application with the Google Analytics API:
1. Go to the Google Developers Console
2. Create a New Project and enable the Google Analytics API
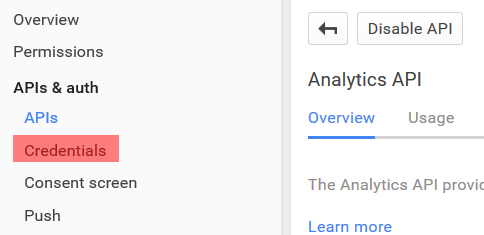
3. On the Credentials screen, create a new Client ID for Application Type “Installed Application”
4. Copy the Client ID and Client Secret to your R Script
Enable Google Analytics API
Create a new Client ID
Now you can authorize the RGoogleAnalytics package to your Google Analytics Account.
client.id <- "your_client_ID_here"
client.secret <- "your_client_secret_here"
token <- Auth(client.id, client.secret)
Save the token into the file
save(token,file="./token")
Continue reading ‘How to extract Google Analytics data in R and Excel’ »